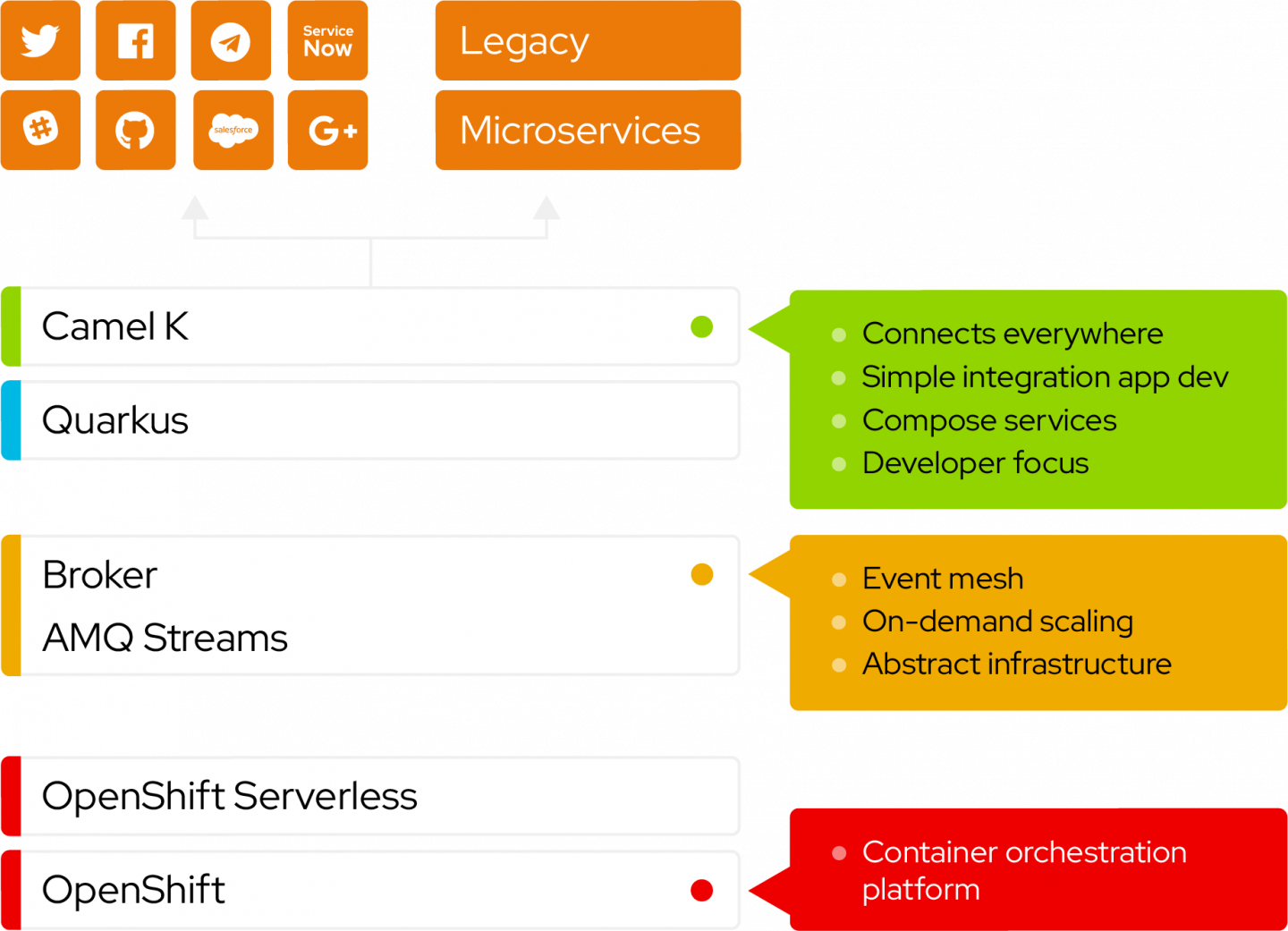
Explore event architecture
You split up your monolithic codebase into smaller artifacts and thought you were done! Now you’ve reached the hardest part: how do you split your data, and how do you keep your system working with it?
If this rings a bell, then you need to watch this DevNation Tech Talk streamed on January 16, 2020. We’ll explore how events with an event-driven architecture can help you succeed in this distributed data world.
Learn concepts like CQRS, event sourcing, and how you can use them in a distributed architecture with REST, message brokers, and Apache Kafka.